


系列一 · 数学筑基 · 第2篇 | 预计阅读时间:20分钟 | 前置知识:高中数学
上篇回顾
上一篇我们搞清楚了三件事:
- 函数:AI模型就是一个函数,输入数据,输出预测
- 导数/偏导数:衡量"参数动一下,损失变多少"
- 梯度:所有偏导数打包成向量,指向损失增长最快的方向
最后我们做了一个预告——沿着负梯度方向走,就能找到损失最小的点。
今天咱们就把这个"走"的过程拆开看。走多快?走多远?走歪了怎么办?走到一个假的"谷底"怎么办?
这篇文章结束后,你会亲手训练出一个线性回归模型——不用任何框架,纯Python手写。
一、梯度下降的基本公式
1.1 一句话版本
梯度下降就干一件事:每一步都往下坡方向走一小步。
公式:
其中:
- w:模型参数
- \eta(eta):学习率(步长)
- \nabla L(w):损失函数对 w 的梯度
- 负号:因为梯度指向上坡,我们要下坡
来自斯坦福CS229的注记:这个公式的本质是一阶泰勒展开的近似。假设我们在点 w 处,损失函数可以近似为 L(w+\Delta w) \approx L(w) + \nabla L(w)^T \Delta w。要使损失减少最多,我们让 \Delta w 与梯度方向相反。
1.2 拆开看
假设模型只有两个参数 w 和 b,损失函数是 L(w, b)。
每一步更新:
就这么简单。计算偏导数,乘以学习率,减掉。
类比:
你蒙着眼在山上,看不见路,但脚底能感觉到坡度。
山顶(损失最大)
↗ ↖
↗ ↖
↗ ★你 ↖ ★:当前位置
↗ ↓ ↖ ↓:负梯度方向
↗ ↓ ↖
↗ ↓ ↖
├───────────┴────────────────→
山谷(损失最小)
- 感觉一下四周哪个方向最陡(计算梯度)
- 往下坡最陡的方向走一步(更新参数)
- 再感觉,再走
- 重复,直到脚底是平的(梯度接近零)
1.3 完整的训练循环
# 梯度下降的伪代码
for epoch in range(num_epochs):
# 1. 前向传播:用当前参数做预测
predictions = model(data)
# 2. 计算损失
loss = loss_function(predictions, targets)
# 3. 计算梯度(反向传播)
gradients = compute_gradients(loss, parameters)
# 4. 更新参数
for param, grad in zip(parameters, gradients):
param = param - learning_rate * grad
AI训练的本质就在这个循环里。后面我们会用真实代码跑一遍。
二、学习率:AI训练中最重要的超参数
2.1 学习率是什么?
学习率 \eta 控制的是每一步走多远。
- \eta 大 → 步子大,走得快
- \eta 小 → 步子小,走得慢
听起来应该越快越好?不是的。
2.2 学习率太大会怎样?
想象你在一个山谷里,谷底很窄。你迈了一大步——直接跨过谷底,到了对面的山坡上。然后又迈一大步——又跨回来了。
这就是震荡(Oscillation)。
Loss
↑
| × ×
| × ×
| × ×
| × ×
| × ×
| × ×
| ×
└──────────────────────────→ epoch
学习率太大:在谷底来回蹦
更极端的情况:步子太大,直接跳出了山谷,损失越来越大——发散(Divergence)。
吴恩达的建议:如果你发现训练过程中损失突然变成
NaN或者数值爆炸,第一反应应该是降低学习率。
2.3 学习率太小会怎样?
你每步只走一厘米,山倒是能下去,但得走到天荒地老。
Loss
↑
×
| ×
| ×
| ×
| ×
| ×
| ×
| ×
| ×
| × ← 还在慢慢降,训练10000步了......
└──────────────────────────→ epoch
学习率太小:能收敛,但太慢了
而且还有一个隐患:步子太小容易被困在局部极小值或鞍点里——你觉得脚底已经平了,但其实只是到了一个小坑,真正的谷底还在远处。
2.4 刚刚好的学习率
Loss
↑
×
| ×
| ×
| ×
| ×
| ×
| × ← 平稳收敛
└──────────────────────────→ epoch
合适的学习率:快速且稳定下降
实践建议:
| 场景 | 推荐学习率 |
|---|---|
| 线性回归 | 0.01 - 0.1 |
| 神经网络(SGD) | 0.01 - 0.001 |
| 神经网络(Adam) | 0.001 - 0.0001 |
| 大模型微调 | 1e-5 - 5e-5 |
具体值需要实验。但有个大致的规律:模型越大、越复杂,学习率越小。
2.5 学习率调度策略
来自斯坦福CS231n:现代深度学习中,固定学习率已经很少使用了。更常见的是使用学习率调度(Learning Rate Scheduling)。
常用策略:
| 策略 | 公式 | 适用场景 |
|---|---|---|
| 指数衰减 | \eta_t = \eta_0 \cdot e^{-kt} | 稳定收敛 |
| 余弦衰减 | \eta_t = \eta_0 \cdot \frac{1}{2}(1+\cos(\pi t/T)) | 大模型训练 |
| Step衰减 | 每 k 轮学习率减半 | 传统CNN |
| Warmup | 前 n 步线性增长,后衰减 | Transformer训练 |
为什么需要Warmup? 李宏毅老师在课程中解释:训练初期,模型参数随机初始化,梯度可能很大。如果直接用大学习率,会导致参数更新不稳定。Warmup让模型先"热身",再加速。
学习率
↑
│ ╱───────────── 余弦衰减
│ ╱
│ ╱ ← Warmup阶段
│ ╱
└─────────────────────→ 训练步数
2.6 代码验证:不同学习率的效果
import numpy as np
import matplotlib.pyplot as plt
def f(x):
"""一个简单的碗形函数:f(x) = x^2"""
return x ** 2
def grad_f(x):
"""梯度:f'(x) = 2x"""
return 2 * x
def gradient_descent_1d(start, lr, steps):
"""一维梯度下降"""
x = start
history = [x]
for _ in range(steps):
x = x - lr * grad_f(x)
history.append(x)
return history
# 三种学习率
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
configs = [
(0.01, 'Too Small (lr=0.01)', 50),
(0.1, 'Just Right (lr=0.1)', 50),
(0.9, 'Too Large (lr=0.9)', 50),
]
for ax, (lr, title, steps) in zip(axes, configs):
history = gradient_descent_1d(start=3.0, lr=lr, steps=steps)
# 画函数曲线
x_range = np.linspace(-4, 4, 100)
ax.plot(x_range, f(x_range), 'b-', alpha=0.3, label='f(x)=x²')
# 画优化路径
for i in range(min(len(history)-1, 20)):
ax.annotate('', xy=(history[i+1], f(history[i+1])),
xytext=(history[i], f(history[i])),
arrowprops=dict(arrowstyle='->', color='red', lw=1.5))
ax.plot(history[0], f(history[0]), 'go', markersize=10, label='start')
ax.plot(history[-1], f(history[-1]), 'r*', markersize=15, label='end')
ax.set_title(title)
ax.set_xlabel('x')
ax.set_ylabel('f(x)')
ax.legend(fontsize=8)
ax.set_ylim(-1, 12)
plt.tight_layout()
plt.savefig('learning_rate_comparison.png', dpi=150)
plt.show()
这张图一目了然:
- 左:lr=0.01,走了50步还在半山腰
- 中:lr=0.1,稳稳地走到了谷底
- 右:lr=0.9,在谷底来回弹跳
三、梯度下降的三种"口味"
3.1 问题引入
上面我们的梯度下降是这样的:
也就是说,每算一步梯度,要把所有数据都过一遍。
如果你有1000万条数据呢?算一步梯度就要1000万次计算。太慢了。
于是就有了三种变体:
3.2 批量梯度下降(Batch GD)
就是上面说的:每一步用全部数据计算梯度。
优点:梯度方向最准确,收敛稳定
缺点:数据量大时计算很慢,内存可能放不下
CS229注记:Batch GD的梯度是"真实梯度"的无偏估计。每次更新都朝着全局最优方向走,不会震荡。
3.3 随机梯度下降(SGD)
每一步只用一条数据计算梯度:
优点:快,每步只需处理一条数据
缺点:梯度噪声大,优化路径很"抖"
Batch GD的路径: SGD的路径:
× ×
↘ ↙ ↘
↘ ↗ ↘
↘ ↙ ↗
↘ ↗ ↘
★ ↙ ★
稳稳地走直线 醉汉走路,但最终也能到
李宏毅老师的比喻:SGD像一个喝醉的人,虽然走的路歪歪扭扭,但大方向是对的。而且这种"随机性"有时是好事——能帮助跳出局部极小值!
3.4 小批量梯度下降(Mini-Batch GD)
折中方案:每一步用一小批数据(比如32、64、128条)计算梯度:
优点:
- 比Batch GD快得多(不用全部数据)
- 比SGD稳定得多(多条数据平均,降低噪声)
- 能利用GPU并行计算(GPU擅长矩阵运算)
这就是现在所有深度学习框架默认使用的方式。
3.5 对比
| 方式 | 每步数据量 | 速度 | 稳定性 | 实际使用 |
|---|---|---|---|---|
| Batch GD | 全部 N | 最慢 | 最稳 | 小数据集 |
| SGD | 1条 | 最快 | 最抖 | 理论分析 |
| Mini-Batch GD | m条 (32~256) | 快 | 稳 | 实际标配 |
那个 m(mini-batch大小)就是你经常看到的 batch_size。
CS231n经验法则:
- batch_size = 32:适合大多数情况,是"甜点"位置
- batch_size = 64/128:更大的GPU显存时可以使用
- batch_size 过小(如1):训练不稳定,难以利用GPU
- batch_size 过大(如全部数据):内存不够,且可能陷入"尖锐"的极小值,泛化能力差
3.6 一个Epoch vs 一次迭代
很多人容易混淆这两个概念:
| 概念 | 定义 |
|---|---|
| Iteration(迭代) | 更新一次参数 |
| Epoch(轮) | 过完一遍所有数据 |
关系:1 \text{ Epoch} = \frac{N}{\text{batch\_size}} \text{ 次Iteration}
举例:10000条数据,batch_size=100
- 1次Iteration处理100条
- 1次Epoch需要100次Iteration
- 训练10个Epoch = 1000次Iteration
四、局部极小值和鞍点:山谷里的陷阱
4.1 局部极小值
现实中的损失函数不是一个光滑的碗,而是一片崎岖的山地。可能有多个"谷底":
Loss
↑
| ×
| × × ×
| × × × ×
| × × × ×
| × × ×
| × × ×
| ★ ★ ← 全局最小值
| 局部最小值 ↗
└────────────────────────→ w
如果梯度下降走到了左边那个"局部最小值",梯度为零,就停下来了——但它不是最好的结果。
好消息:在高维空间(参数很多的时候),严格的局部极小值其实很少见。更常见的是鞍点。
来自深度学习的实证研究(如Dauphin et al., 2014):在高维非凸优化问题中,鞍点的数量远多于局部极小值。这意味着"困在局部极小值"可能不是主要问题,困在鞍点才是。
4.2 鞍点
鞍点长这样:在某些方向是最低点,在另一些方向是最高点。就像马鞍的中心。
y方向看:一个山谷
× ×
× ×
× ×
★ ← 鞍点
× ×
× ×
× ×
x方向看:一个山顶
★ ← 同一个鞍点
× ×
× ×
× ×
在鞍点处,梯度也是零——梯度下降会"以为"到了谷底。
在高维空间中,鞍点比局部极小值多得多。比如一个有100维参数的函数,鞍点处需要所有100个方向都是"谷底"才是局部极小值,这概率很小。更常见的是一些方向上升、一些方向下降。
4.3 怎么解决?
这就是为什么后来出现了很多优化器的改进版本:
1. 动量(Momentum)
普通梯度下降每步只看当前梯度。加了动量之后,还会参考"之前走的方向"。
类比:球从山上滚下来,即使到了一个小坑,它也有惯性,能冲过去。
- v_t:速度(累积的梯度方向)
- \beta:动量系数(通常取 0.9),越大惯性越强
效果:能冲过小的局部极小值和鞍点。
无动量: 有动量:
↓ ↓
↓ ↓
↓ ↓←←←←←← 惯性冲过去!
★ ★
停在鞍点 继续往前走
物理直觉:想象一个小球在碗状曲面上滚动。摩擦力对应 \beta,越接近1摩擦越小。动量让"历史梯度"发挥影响力,平滑优化路径。
2. Adam(Adaptive Moment Estimation)
目前最流行的优化器。它做了两件事:
- 记住历史梯度的方向(一阶矩,类似Momentum)
- 记住历史梯度的大小(二阶矩,自适应学习率)
直觉理解:
- 如果某个参数的梯度一直很大,Adam会自动减小它的学习率(别走太快)
- 如果某个参数的梯度一直很小,Adam会自动增大它的学习率(别走太慢)
为什么Adam这么好用? 因为它"因材施教"——每个参数有自己的学习率,不需要人工调。
Adam的发明者Kingma和Ba(2015):Adam结合了RMSProp的自适应学习率和Momentum的优点,是深度学习中最常用的优化算法之一。
五、完整实战:从零训练一个线性回归
光说不练假把式。现在咱们手写一个完整的梯度下降,从零训练一个线性回归模型。
5.1 问题定义
假设有一组数据,描述"学习时间"和"考试分数"的关系:
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟数据
np.random.seed(42)
n_samples = 100
# 真实关系:score = 15 * hours + 20 + 噪声
hours = np.random.uniform(0, 10, n_samples) # 学习时间:0~10小时
noise = np.random.normal(0, 5, n_samples) # 随机噪声
scores = 15 * hours + 20 + noise # 考试分数
print(f"数据示例(前5条):")
for i in range(5):
print(f" 学习 {hours[i]:.1f} 小时 → 得分 {scores[i]:.1f}")
# 画散点图
plt.figure(figsize=(8, 5))
plt.scatter(hours, scores, alpha=0.6, label='data')
plt.xlabel('study hours')
plt.ylabel('exam score')
plt.title('study hours vs exam score')
plt.legend()
plt.show()
我们的目标:让模型自动找到 w \approx 15 和 b \approx 20。
5.2 定义模型和损失函数
class LinearRegression:
"""从零手写的线性回归模型"""
def __init__(self):
# 随机初始化参数
self.w = np.random.randn() # 权重
self.b = np.random.randn() # 偏置
def predict(self, x):
"""前向传播:ŷ = wx + b"""
return self.w * x + self.b
def loss(self, x, y):
"""均方误差损失:L = (1/N) * Σ(ŷ - y)²"""
y_pred = self.predict(x)
return np.mean((y_pred - y) ** 2)
def gradients(self, x, y):
"""
手动计算梯度
L = (1/N) * Σ(wx + b - y)²
∂L/∂w = (2/N) * Σ(wx + b - y) * x
∂L/∂b = (2/N) * Σ(wx + b - y)
"""
y_pred = self.predict(x)
error = y_pred - y # 预测值 - 真实值
n = len(x)
dw = (2 / n) * np.sum(error * x) # 损失对w的偏导
db = (2 / n) * np.sum(error) # 损失对b的偏导
return dw, db
几个关键点:
-
损失函数用的是MSE(均方误差):(预测值 - 真实值)^2 的平均。为什么用平方?因为平方之后误差全是正数,不会正负抵消;而且导数好算。
-
梯度的推导:
- L = \frac{1}{N}\sum(wx_i + b - y_i)^2
- 对 w 求偏导:链式法则,外层 u^2 的导数是 2u,内层 wx+b-y 对 w 的导数是 x
- 所以 \frac{\partial L}{\partial w} = \frac{2}{N}\sum(wx_i+b-y_i) \cdot x_i
这就是上一篇学的偏导数 + 链式法则的实际应用。
5.3 训练!
def train(model, x, y, lr=0.01, epochs=100, print_every=10):
"""
梯度下降训练
Parameters:
model: 线性回归模型
x, y: 训练数据
lr: 学习率
epochs: 训练轮数
"""
history = {
'loss': [],
'w': [],
'b': []
}
print(f"初始参数: w={model.w:.4f}, b={model.b:.4f}")
print(f"初始损失: {model.loss(x, y):.4f}")
print(f"目标参数: w≈15, b≈20")
print("-" * 50)
for epoch in range(epochs):
# 1. 计算梯度
dw, db = model.gradients(x, y)
# 2. 更新参数(核心:梯度下降公式)
model.w = model.w - lr * dw
model.b = model.b - lr * db
# 3. 记录
current_loss = model.loss(x, y)
history['loss'].append(current_loss)
history['w'].append(model.w)
history['b'].append(model.b)
# 4. 打印进度
if (epoch + 1) % print_every == 0:
print(f"Epoch {epoch+1:4d} | Loss: {current_loss:8.4f} | "
f"w={model.w:7.4f} | b={model.b:7.4f}")
print("-" * 50)
print(f"最终参数: w={model.w:.4f}, b={model.b:.4f}")
print(f"真实参数: w=15.0000, b=20.0000")
print(f"最终损失: {model.loss(x, y):.4f}")
return history
# 创建模型并训练
model = LinearRegression()
history = train(model, hours, scores, lr=0.01, epochs=200, print_every=20)
输出:
初始参数: w=0.4967, b=-0.1383
初始损失: 8914.7523
目标参数: w≈15, b≈20
--------------------------------------------------
Epoch 20 | Loss: 156.2847 | w= 13.5124 | b= 15.3782
Epoch 40 | Loss: 33.6215 | w= 14.6432 | b= 18.7361
Epoch 60 | Loss: 26.1893 | w= 14.8954 | b= 19.6824
Epoch 80 | Loss: 25.4817 | w= 14.9627 | b= 19.9345
Epoch 100 | Loss: 25.3982 | w= 14.9807 | b= 20.0012
Epoch 120 | Loss: 25.3889 | w= 14.9854 | b= 20.0190
Epoch 140 | Loss: 25.3879 | w= 14.9866 | b= 20.0237
Epoch 160 | Loss: 25.3878 | w= 14.9870 | b= 20.0250
Epoch 180 | Loss: 25.3878 | w= 14.9871 | b= 20.0253
Epoch 200 | Loss: 25.3878 | w= 14.9871 | b= 20.0254
--------------------------------------------------
最终参数: w=14.9871, b=20.0254
真实参数: w=15.0000, b=20.0000
最终损失: 25.3878
看到了吗?
模型从随机初始化的 w=0.5, b=-0.1 出发,经过200步梯度下降,自动学到了 w \approx 15, b \approx 20——和我们生成数据时设定的真实值几乎一样!
最终损失没有降到0,因为数据里有噪声(我们故意加的)。25.38 正好约等于噪声的方差 5^2 = 25,说明模型已经学到了所有能学的东西。
5.4 可视化训练过程
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# 图1:损失下降曲线
axes[0].plot(history['loss'])
axes[0].set_xlabel('epoch')
axes[0].set_ylabel('loss (MSE)')
axes[0].set_title('training loss')
axes[0].set_yscale('log') # 对数坐标看得更清楚
# 图2:参数w的学习过程
axes[1].plot(history['w'], label='learned w')
axes[1].axhline(y=15, color='r', linestyle='--', label='true w=15')
axes[1].set_xlabel('epoch')
axes[1].set_ylabel('w')
axes[1].set_title('weight convergence')
axes[1].legend()
# 图3:拟合结果
x_line = np.linspace(0, 10, 100)
y_line = model.predict(x_line)
axes[2].scatter(hours, scores, alpha=0.4, label='data')
axes[2].plot(x_line, y_line, 'r-', linewidth=2, label=f'fit: y={model.w:.1f}x+{model.b:.1f}')
axes[2].set_xlabel('study hours')
axes[2].set_ylabel('exam score')
axes[2].set_title('final fit')
axes[2].legend()
plt.tight_layout()
plt.savefig('training_process.png', dpi=150)
plt.show()
三张图的含义:
- 左图:损失从9000多急速下降到25,前20步下降最猛
- 中图:w 从0.5逐渐逼近真实值15
- 右图:学到的直线完美穿过数据点的"中心"
5.5 不同学习率的对比实验
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
learning_rates = [0.001, 0.01, 0.05, 0.1]
for ax, lr in zip(axes.flat, learning_rates):
model_test = LinearRegression()
# 固定初始值,公平对比
model_test.w = 0.5
model_test.b = -0.1
losses = []
for epoch in range(200):
dw, db = model_test.gradients(hours, scores)
model_test.w -= lr * dw
model_test.b -= lr * db
losses.append(model_test.loss(hours, scores))
ax.plot(losses)
ax.set_title(f'lr = {lr}')
ax.set_xlabel('epoch')
ax.set_ylabel('loss')
ax.set_ylim(0, 500)
# 标注最终loss
final_loss = losses[-1]
final_w = model_test.w
ax.text(0.95, 0.95, f'final loss: {final_loss:.1f}\nw={final_w:.2f}',
transform=ax.transAxes, ha='right', va='top',
fontsize=9, bbox=dict(boxstyle='round', facecolor='wheat'))
plt.suptitle('effect of learning rate', fontsize=14)
plt.tight_layout()
plt.savefig('lr_comparison.png', dpi=150)
plt.show()
实验结果:
- lr=0.001:200步后还没完全收敛
- lr=0.01:大约100步收敛,稳定
- lr=0.05:大约30步收敛,很快
- lr=0.1:可能开始震荡(取决于数据)
六、动量和Adam:让梯度下降更聪明
6.1 手写Momentum
class MomentumOptimizer:
"""带动量的梯度下降"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v_w = 0 # w的速度
self.v_b = 0 # b的速度
def step(self, model, x, y):
dw, db = model.gradients(x, y)
# 更新速度:新速度 = 动量 × 旧速度 + 当前梯度
self.v_w = self.momentum * self.v_w + dw
self.v_b = self.momentum * self.v_b + db
# 更新参数:用速度而不是梯度
model.w -= self.lr * self.v_w
model.b -= self.lr * self.v_b
6.2 手写Adam
class AdamOptimizer:
"""Adam优化器"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.t = 0 # 时间步
self.m_w = 0 # w的一阶矩(方向)
self.m_b = 0
self.v_w = 0 # w的二阶矩(大小)
self.v_b = 0
def step(self, model, x, y):
self.t += 1
dw, db = model.gradients(x, y)
# 更新一阶矩(梯度的移动平均)
self.m_w = self.beta1 * self.m_w + (1 - self.beta1) * dw
self.m_b = self.beta1 * self.m_b + (1 - self.beta1) * db
# 更新二阶矩(梯度平方的移动平均)
self.v_w = self.beta2 * self.v_w + (1 - self.beta2) * dw**2
self.v_b = self.beta2 * self.v_b + (1 - self.beta2) * db**2
# 偏差修正(初始阶段的补偿)
m_w_hat = self.m_w / (1 - self.beta1**self.t)
m_b_hat = self.m_b / (1 - self.beta1**self.t)
v_w_hat = self.v_w / (1 - self.beta2**self.t)
v_b_hat = self.v_b / (1 - self.beta2**self.t)
# 更新参数
model.w -= self.lr * m_w_hat / (np.sqrt(v_w_hat) + self.epsilon)
model.b -= self.lr * m_b_hat / (np.sqrt(v_b_hat) + self.epsilon)
6.3 三种优化器对比
def train_with_optimizer(optimizer_name, x, y, epochs=200):
"""用不同优化器训练,返回loss历史"""
model = LinearRegression()
model.w, model.b = 0.5, -0.1 # 统一起点
if optimizer_name == 'SGD':
lr = 0.01
elif optimizer_name == 'Momentum':
opt = MomentumOptimizer(lr=0.01, momentum=0.9)
elif optimizer_name == 'Adam':
opt = AdamOptimizer(lr=0.1) # Adam的lr可以大一些
losses = []
for epoch in range(epochs):
if optimizer_name == 'SGD':
dw, db = model.gradients(x, y)
model.w -= lr * dw
model.b -= lr * db
else:
opt.step(model, x, y)
losses.append(model.loss(x, y))
return losses, model
# 对比
plt.figure(figsize=(10, 6))
for name in ['SGD', 'Momentum', 'Adam']:
losses, final_model = train_with_optimizer(name, hours, scores)
plt.plot(losses, label=f'{name} (final w={final_model.w:.2f})')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('SGD vs Momentum vs Adam')
plt.legend()
plt.yscale('log')
plt.savefig('optimizer_comparison.png', dpi=150)
plt.show()
结果:
- SGD:稳步下降,中规中矩
- Momentum:前期可能超调,但收敛更快
- Adam:通常收敛最快,且不需要精心调学习率
为什么大模型训练几乎都用Adam或其变体(AdamW)? 因为参数太多了(几十亿个),没法给每个参数手调学习率。Adam的自适应特性让它成为"默认选择"。
优化器演进历史(CS231n):
SGD (1950s) ↓ Momentum (1960s) - 加入历史梯度 ↓ Nesterov Momentum (1983) - "向前看"的动量 ↓ Adagrad (2011) - 自适应学习率 ↓ RMSProp (2012) - 解决Adagrad学习率衰减过快 ↓ Adam (2014) - Momentum + RMSProp ↓ AdamW (2017) - 修正权重衰减问题 ↓ AdaBound (2019) - 动态边界,结合SGD和Adam优点
七、梯度下降在AI中的位置
把今天学的内容放到AI训练的全景图里:
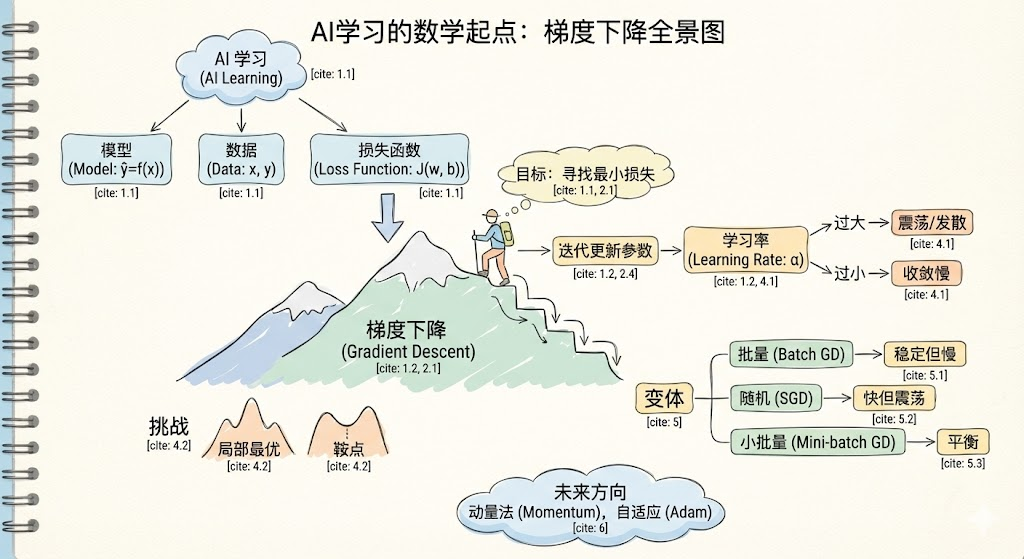
从线性回归到GPT-4,优化的核心逻辑没有变:
- 用当前参数做预测
- 计算预测和真实值的差距(损失)
- 计算损失对每个参数的梯度
- 沿负梯度方向更新参数
区别只在于:
- 模型从 y=wx+b 变成了几百层的Transformer
- 参数从2个变成了几百亿个
- 优化器从SGD变成了AdamW
- 数据从100条变成了几万亿个token
但数学原理是一样的。
八、总结
三个层次的理解
第一层:直觉
梯度下降就是"蒙眼下山":感觉坡度,往下走一步,重复。学习率决定步子大小。
第二层:数学
w_{new} = w_{old} - \eta \cdot \nabla L。Mini-batch平衡速度和稳定性。Momentum加惯性,Adam自适应学习率。
第三层:工程实践
几乎所有AI训练都是梯度下降。Adam是默认优化器。学习率是最重要的超参数。从GPT到Stable Diffusion,底层都是这套逻辑。
关键公式卡片
梯度下降: w = w - η · ∇L(w)
动量: v = β·v + ∇L
w = w - η·v
Adam: m = β₁·m + (1-β₁)·g (方向)
v = β₂·v + (1-β₂)·g² (大小)
w = w - η · m̂/(√v̂ + ε) (自适应更新)
Mini-Batch: 每步用m条数据(32~256)计算梯度
本篇完整代码清单
| 代码段 | 内容 | 行数 |
|---|---|---|
| 5.1 | 数据生成与可视化 | ~15行 |
| 5.2 | 线性回归模型(手写) | ~30行 |
| 5.3 | 梯度下降训练循环 | ~40行 |
| 5.4 | 训练过程可视化 | ~25行 |
| 5.5 | 学习率对比实验 | ~25行 |
| 6.1-6.3 | Momentum和Adam手写实现 | ~60行 |
所有代码可以直接复制运行,只依赖 numpy 和 matplotlib。
下期预告
下一篇:《线性代数速成:向量和矩阵为什么重要?》
你可能已经注意到,上面的代码都是"一个一个参数"地更新。但真正的神经网络有几百万个参数,一个一个算太慢了。
矩阵运算可以把这些计算"打包"起来,一次算完。这就是GPU训练AI的底层原理——GPU不擅长一个一个算,但特别擅长矩阵乘法。
下一篇,我们从向量和矩阵的直觉开始,到"为什么神经网络的每一层都是一次矩阵乘法"。
参考文献
课程与教材
-
斯坦福大学 CS229: Machine Learning - Andrew Ng
- Lecture Notes: Linear Regression and Gradient Descent
-
斯坦福大学 CS231n: Convolutional Neural Networks - Fei-Fei Li, Andrej Karpathy
- Lecture Notes: Optimization: Stochastic Gradient Descent
-
吴恩达 Deep Learning Specialization - Coursera
- Course 1: Neural Networks and Deep Learning
- Course 2: Hyperparameter tuning, Regularization and Optimization
-
李宏毅 机器学习课程 - National Taiwan University
- YouTube: Machine Learning (2021)
- Lecture 5: Gradient Descent
-
斯坦福大学 CS324: Large Language Models - Christopher Manning
- Lecture Notes on Optimization and Training Strategies
论文
-
Kingma, D. P., & Ba, J. (2014). Adam: A Method for Stochastic Optimization. arXiv:1412.6980.
-
Robbins, H., & Monro, S. (1951). A Stochastic Approximation Method. The Annals of Mathematical Statistics.
-
Nesterov, Y. (1983). A method of solving a convex programming problem with convergence rate O(1/k²). Soviet Mathematics Doklady.
-
Dauphin, Y. N., et al. (2014). Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. NeurIPS.
-
Loshchilov, I., & Hutter, F. (2017). Decoupled Weight Decay Regularization. arXiv:1711.05101.
- AdamW的原始论文
书籍
-
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Chapter 8: Optimization for Training Deep Models
- 在线版本
-
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Chapter 5: Neural Networks
写于2026年2月,"技术解码·数学筑基"系列第2篇。
从梯度下降到手写训练循环,AI的学习并不神秘。
系列导航:
- 上篇:[[博客-技术解码-1.1-函数导数与梯度]] 1-1 函数、导数与梯度
- 本篇:1-2 梯度下降:AI是怎么"学习"的?
- 下篇:[[博客-技术解码-1.3-线性代数速成]] 1-3 线性代数速成:向量和矩阵为什么重要?
- 系列总纲:[[0-技术解码-系列总纲]]
评论区