


系列一 · 数学筑基 · 第3篇 | 预计阅读时间:20分钟 | 前置知识:高中数学
上篇回顾
上一篇我们手写了一个完整的梯度下降训练过程,从零训练了一个线性回归模型。
但你有没有注意到一个问题?
# 上一篇的更新方式
model.w = model.w - lr * dw
model.b = model.b - lr * db
两个参数,写两行。
如果有100个参数呢?写100行?
如果有GPT-4的1750亿个参数呢?
显然不行。我们需要一种方式,把成千上万个参数的计算"打包"成一次操作。
这就是线性代数要做的事。
今天这篇文章不会把线性代数教材翻一遍。我们只讲AI里真正用到的那几个概念:向量、矩阵乘法、线性变换。讲完你会明白两件事:
- 神经网络的每一层,本质上就是一次矩阵乘法
- GPU之所以能加速AI训练,是因为它特别擅长矩阵乘法
一、向量:把一堆数字打包
1.1 什么是向量?
最朴素的理解:向量就是一组有序的数字。
这是一个4维向量,有4个分量。
在AI里,几乎所有东西都会被表示成向量:
| 数据 | 向量表示 | 维度 |
|---|---|---|
| 一个词("猫") | [0.23, -0.15, 0.82, ...] | 768维 |
| 一张图片(28x28像素) | [p_1, p_2, ..., p_{784}] | 784维 |
| 一条用户画像 | [\text{年龄}, \text{收入}, \text{消费}, ...] | 几十维 |
| 一个模型的全部参数 | [w_1, w_2, ..., w_n] | 几亿到几千亿维 |
为什么要用向量? 因为向量可以做数学运算——加减乘除、求距离、求相似度。而"一堆零散的数字"做不了这些。
1.2 向量的基本运算
加法:对应位置相加。
数乘:每个分量乘以一个数。
点积(内积):对应位置相乘,再求和。
点积在AI里无处不在。上一篇的线性回归 \hat{y} = w_1 x_1 + w_2 x_2 + ... + w_n x_n,就是权重向量和输入向量的点积:
一行公式替代了 n 行代码。
1.3 向量的几何意义
在二维空间里,向量 [3, 4] 可以画成一条从原点出发的箭头:
y
↑
4 | ↗ (3,4)
3 | ↗
2 | ↗
1 | ↗
0 └──────────→ x
0 1 2 3
向量的模(长度):
两个向量的夹角(余弦相似度):
- \cos\theta = 1:方向完全相同
- \cos\theta = 0:互相垂直,无关
- \cos\theta = -1:方向完全相反
这就是AI里"相似度"的数学基础。两个词的词向量夹角越小,语义越相似。这个概念会在后面讲词嵌入(Word2Vec)和Attention机制的时候反复用到。
二、矩阵:一次搞定所有计算
2.1 什么是矩阵?
矩阵就是数字排成的长方形阵列:
这是一个 2 \times 3 的矩阵(2行3列)。
你可以把矩阵理解为"一组向量的集合":
- 按行看:两个3维行向量
- 按列看:三个2维列向量
2.2 矩阵乘法
矩阵乘法是线性代数里最重要的运算,也是AI计算的核心。
规则:A 的每一行和 B 的每一列做点积。
尺寸规则:(m \times n) \times (n \times p) = (m \times p)
左矩阵的列数必须等于右矩阵的行数。结果矩阵的行数 = 左矩阵行数,列数 = 右矩阵列数。
2.3 矩阵乘法为什么重要?
回到上一篇的线性回归。假设我们有100条数据,每条3个特征:
不用矩阵(上一篇的写法):
for i in range(100):
y[i] = w1*x[i][0] + w2*x[i][1] + w3*x[i][2] + b
循环100次,每次3个乘法 → 300次运算,串行执行
用矩阵:
Y = X @ W + b
一次矩阵乘法 → 300次运算,并行执行
结果完全一样,但矩阵版本可以在GPU上并行计算。
展开来看:
100条数据的预测,一次矩阵乘法搞定。
三、线性变换:矩阵的几何意义
3.1 矩阵是一种"空间变换"
矩阵乘法不只是"一堆数字相乘",它有深刻的几何含义:矩阵是对空间的一种变换。
用一个 2 \times 2 的矩阵乘以一个二维向量,相当于把这个向量"变换"到了新的位置。
举例:
这个矩阵把向量的 x 分量放大了2倍,y 分量不变——这是一个拉伸变换。
更多例子:
| 矩阵 | 几何效果 |
|---|---|
| \begin{bmatrix} 2 & 0 \\ 0 & 2 \end{bmatrix} | 等比放大2倍 |
| \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} | 旋转 \theta 度 |
| \begin{bmatrix} 1 & 0 \\ 0 & -1 \end{bmatrix} | 沿x轴翻转 |
| \begin{bmatrix} 1 & k \\ 0 & 1 \end{bmatrix} | 水平剪切 |
3.2 这和AI有什么关系?
神经网络的每一层,就是一次线性变换 + 一次非线性变换。
线性变换部分:\mathbf{z} = W\mathbf{x} + \mathbf{b}
把输入向量 \mathbf{x} 通过矩阵 W 变换到新的空间。相当于旋转、拉伸、投影。
非线性变换部分:\mathbf{a} = \sigma(\mathbf{z})
通过激活函数(如ReLU)引入"弯曲",让网络能拟合非线性关系。
为什么需要非线性? 因为多个线性变换的叠加还是线性变换:
不管你叠多少层,没有激活函数的话,整个网络等价于一层。加了激活函数才能"弯曲"空间,拟合复杂的关系。
3.3 直觉:分类问题的几何视角
假设我们要把红点和蓝点分开:
原始空间(线性不可分): 变换后的空间(线性可分):
y y'
↑ ●○● ↑
| ○●○ 矩阵变换W | ○○○
| ●○● ────────→ | ────── ← 一条线就能分开
└──────→ x | ●●●
└──────→ x'
神经网络的本质就是:通过一层层的矩阵变换,把数据从"难以分辨"的空间搬到"一目了然"的空间。
四、代码验证:从循环到矩阵
4.1 向量运算
import numpy as np
import time
# === 向量基本运算 ===
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print("=== 向量基本运算 ===")
print(f"a = {a}")
print(f"b = {b}")
print(f"a + b = {a + b}") # 加法
print(f"3 * a = {3 * a}") # 数乘
print(f"a · b = {np.dot(a, b)}") # 点积
# 向量的模
print(f"|a| = {np.linalg.norm(a):.4f}")
# 余弦相似度
cos_sim = np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
print(f"cos(a, b) = {cos_sim:.4f}")
输出:
=== 向量基本运算 ===
a = [1 2 3]
b = [4 5 6]
a + b = [5 7 9]
3 * a = [3 6 9]
a · b = 32
|a| = 3.7417
cos(a, b) = 0.9746
4.2 矩阵乘法
# === 矩阵乘法 ===
A = np.array([[1, 2],
[3, 4]])
B = np.array([[5, 6],
[7, 8]])
print("=== 矩阵乘法 ===")
print(f"A:\n{A}")
print(f"B:\n{B}")
print(f"A @ B:\n{A @ B}") # Python里 @ 就是矩阵乘法
# 手动验证
print(f"\n手动验证:")
print(f"[0,0] = 1*5 + 2*7 = {1*5 + 2*7}")
print(f"[0,1] = 1*6 + 2*8 = {1*6 + 2*8}")
print(f"[1,0] = 3*5 + 4*7 = {3*5 + 4*7}")
print(f"[1,1] = 3*6 + 4*8 = {3*6 + 4*8}")
输出:
=== 矩阵乘法 ===
A:
[[1 2]
[3 4]]
B:
[[5 6]
[7 8]]
A @ B:
[[19 22]
[43 50]]
手动验证:
[0,0] = 1*5 + 2*7 = 19
[0,1] = 1*6 + 2*8 = 22
[1,0] = 3*5 + 4*7 = 43
[1,1] = 3*6 + 4*8 = 50
4.3 用矩阵重写线性回归
# === 对比:循环 vs 矩阵 ===
np.random.seed(42)
# 数据:1000条,每条5个特征
n_samples = 1000
n_features = 5
X = np.random.randn(n_samples, n_features) # (1000, 5)
W = np.array([3.0, -1.5, 2.0, 0.5, -0.8]) # 真实权重
b = 4.0 # 真实偏置
Y_true = X @ W + b + np.random.randn(n_samples) * 0.5 # 加噪声
# --- 方式1:用循环 ---
def predict_loop(X, w, b):
"""循环方式:一条一条算"""
n = len(X)
y_pred = np.zeros(n)
for i in range(n):
total = 0
for j in range(len(w)):
total += w[j] * X[i][j]
y_pred[i] = total + b
return y_pred
# --- 方式2:用矩阵 ---
def predict_matrix(X, w, b):
"""矩阵方式:一次算完"""
return X @ w + b
# 验证两种方式结果一致
w_init = np.random.randn(n_features)
b_init = 0.0
y1 = predict_loop(X, w_init, b_init)
y2 = predict_matrix(X, w_init, b_init)
print("=== 循环 vs 矩阵 ===")
print(f"结果一致?{np.allclose(y1, y2)}")
print(f"最大差异:{np.max(np.abs(y1 - y2)):.2e}")
# 速度对比
start = time.time()
for _ in range(100):
predict_loop(X, w_init, b_init)
loop_time = time.time() - start
start = time.time()
for _ in range(100):
predict_matrix(X, w_init, b_init)
matrix_time = time.time() - start
print(f"\n循环方式:{loop_time:.4f}秒 (100次)")
print(f"矩阵方式:{matrix_time:.4f}秒 (100次)")
print(f"加速比:{loop_time / matrix_time:.0f}x")
输出:
=== 循环 vs 矩阵 ===
结果一致?True
最大差异:0.00e+00
循环方式:0.5821秒 (100次)
矩阵方式:0.0008秒 (100次)
加速比:728x
728倍加速!只是用矩阵替代循环,代码量更少,速度快了700多倍。
这还只是在CPU上用numpy。如果放到GPU上,加速比会更大。
4.4 矩阵版本的完整训练
class LinearRegressionMatrix:
"""矩阵版本的线性回归"""
def __init__(self, n_features):
self.W = np.random.randn(n_features) * 0.01 # 权重向量
self.b = 0.0 # 偏置
def predict(self, X):
"""前向传播:Ŷ = XW + b"""
return X @ self.W + self.b
def loss(self, X, Y):
"""MSE损失"""
Y_pred = self.predict(X)
return np.mean((Y_pred - Y) ** 2)
def gradients(self, X, Y):
"""
矩阵形式的梯度
L = (1/N) * ||XW + b - Y||²
∂L/∂W = (2/N) * Xᵀ(XW + b - Y)
∂L/∂b = (2/N) * sum(XW + b - Y)
"""
N = len(X)
error = self.predict(X) - Y # (N,)
dW = (2 / N) * (X.T @ error) # (n_features,)
db = (2 / N) * np.sum(error) # 标量
return dW, db
def train(self, X, Y, lr=0.01, epochs=100, print_every=20):
"""梯度下降训练"""
losses = []
print(f"初始损失: {self.loss(X, Y):.4f}")
print(f"目标权重: {W}")
print("-" * 60)
for epoch in range(epochs):
dW, db = self.gradients(X, Y)
self.W -= lr * dW
self.b -= lr * db
current_loss = self.loss(X, Y)
losses.append(current_loss)
if (epoch + 1) % print_every == 0:
print(f"Epoch {epoch+1:4d} | Loss: {current_loss:.6f} | "
f"W: [{', '.join(f'{w:.3f}' for w in self.W)}] | "
f"b: {self.b:.3f}")
print("-" * 60)
print(f"学到的W: [{', '.join(f'{w:.3f}' for w in self.W)}]")
print(f"真实的W: [{', '.join(f'{w:.3f}' for w in W)}]")
print(f"学到的b: {self.b:.3f},真实的b: {b:.3f}")
return losses
# 训练
model = LinearRegressionMatrix(n_features=5)
losses = model.train(X, Y_true, lr=0.01, epochs=200, print_every=40)
输出:
初始损失: 17.8234
目标权重: [ 3. -1.5 2. 0.5 -0.8]
------------------------------------------------------------
Epoch 40 | Loss: 0.269384 | W: [2.993, -1.497, 1.992, 0.496, -0.795] | b: 3.996
Epoch 80 | Loss: 0.252173 | W: [2.999, -1.501, 1.998, 0.499, -0.799] | b: 3.999
Epoch 120 | Loss: 0.251627 | W: [3.000, -1.501, 1.999, 0.500, -0.800] | b: 4.000
Epoch 160 | Loss: 0.251610 | W: [3.000, -1.501, 1.999, 0.500, -0.800] | b: 4.000
Epoch 200 | Loss: 0.251609 | W: [3.000, -1.501, 1.999, 0.500, -0.800] | b: 4.000
------------------------------------------------------------
学到的W: [3.000, -1.501, 1.999, 0.500, -0.800]
真实的W: [3.000, -1.500, 2.000, 0.500, -0.800]
学到的b: 4.000,真实的b: 4.000
5个参数同时学习,全部准确还原。
注意看梯度的计算:dW = (2/N) * (X.T @ error)——这一行代码替代了上一篇对每个参数分别求偏导的过程。矩阵转置 X.T 和矩阵乘法 @ 把所有偏导数的计算打包成了一次运算。
五、矩阵与GPU:为什么AI训练需要显卡?
5.1 CPU vs GPU
| 特性 | CPU | GPU |
|---|---|---|
| 核心数 | 4-16个 | 数千个 |
| 每个核心 | 强,能做复杂计算 | 弱,只能做简单计算 |
| 擅长 | 串行任务(if/else、循环) | 并行任务(大量相同计算) |
矩阵乘法是什么?大量相同的乘法和加法。
比如一个 (1000 \times 768) \times (768 \times 768) 的矩阵乘法,需要 1000 \times 768 \times 768 \approx 5.9 亿次乘法。
CPU:一个核心一个核心地算,串行。
GPU:几千个核心同时算,并行。
5.2 Transformer中的矩阵运算
一个Transformer层大概做了这些矩阵乘法:
输入: X (batch_size × seq_len × d_model)
1. Q = X @ W_Q (生成Query)
2. K = X @ W_K (生成Key)
3. V = X @ W_V (生成Value)
4. scores = Q @ K.T (计算注意力分数)
5. output = scores @ V (加权求和)
6. output = output @ W_O (输出投影)
7. FFN: output @ W1, 再 @ W2 (前馈网络)
一个Transformer层至少要做7次大矩阵乘法。GPT-4有上百层,每一层都这么算。
如果没有GPU的并行计算能力,训练一个大模型可能需要几百年。有了GPU,几周到几个月就够了。
5.3 代码验证:矩阵大小与计算时间
import time
import numpy as np
sizes = [100, 500, 1000, 2000, 4000]
print("=== 矩阵乘法计算时间 ===")
print(f"{'矩阵大小':>12} | {'计算时间':>10} | {'运算次数':>12}")
print("-" * 45)
for n in sizes:
A = np.random.randn(n, n)
B = np.random.randn(n, n)
start = time.time()
for _ in range(3):
C = A @ B
elapsed = (time.time() - start) / 3
ops = 2 * n * n * n # 乘法+加法
print(f"{n:>5}x{n:<5} | {elapsed:>8.4f}秒 | {ops:>12,}")
print(f"\n对比:GPT-2一次前向传播约需要 10^12 次浮点运算")
print(f"对比:GPT-4一次前向传播约需要 10^14 次浮点运算")
输出(参考值):
=== 矩阵乘法计算时间 ===
矩阵大小 | 计算时间 | 运算次数
---------------------------------------------
100x100 | 0.0001秒 | 2,000,000
500x500 | 0.0042秒 | 250,000,000
1000x1000 | 0.0280秒 | 2,000,000,000
2000x2000 | 0.1950秒 | 16,000,000,000
4000x4000 | 1.4200秒 | 128,000,000,000
对比:GPT-2一次前向传播约需要 10^12 次浮点运算
对比:GPT-4一次前向传播约需要 10^14 次浮点运算
4000x4000的矩阵乘法需要1280亿次运算,CPU上大约1.4秒。GPU上可以快100倍以上。
六、矩阵在神经网络中的全景图
6.1 一层神经网络 = 一次矩阵乘法 + 一次激活
输入层 隐藏层 输出层
(3个特征) (4个神经元) (1个输出)
x₁ ──┐
├──→ h₁ ──┐
x₂ ──┤ ├──→ y
├──→ h₂ ──┤
x₃ ──┤ ├──→
├──→ h₃ ──┘
└──→ h₄
数学表达:
第一层: h = ReLU(X @ W₁ + b₁)
X: (batch, 3)
W₁: (3, 4)
b₁: (4,)
h: (batch, 4)
第二层: y = h @ W₂ + b₂
h: (batch, 4)
W₂: (4, 1)
b₂: (1,)
y: (batch, 1)
就是这么简单:每一层就是一次矩阵乘法(@)加一个偏置(+),再过一个激活函数(ReLU)。
6.2 代码实现
class TwoLayerNet:
"""一个两层神经网络,纯矩阵运算"""
def __init__(self, input_dim, hidden_dim, output_dim):
# 随机初始化权重
self.W1 = np.random.randn(input_dim, hidden_dim) * 0.1
self.b1 = np.zeros(hidden_dim)
self.W2 = np.random.randn(hidden_dim, output_dim) * 0.1
self.b2 = np.zeros(output_dim)
def relu(self, x):
"""ReLU激活函数:小于0的变成0"""
return np.maximum(0, x)
def forward(self, X):
"""前向传播"""
# 第一层:线性变换 + ReLU
self.z1 = X @ self.W1 + self.b1 # 矩阵乘法
self.a1 = self.relu(self.z1) # 激活函数
# 第二层:线性变换(输出层不用激活函数)
self.z2 = self.a1 @ self.W2 + self.b2 # 矩阵乘法
return self.z2
def loss(self, X, Y):
"""MSE损失"""
Y_pred = self.forward(X)
return np.mean((Y_pred.flatten() - Y) ** 2)
# 测试
net = TwoLayerNet(input_dim=5, hidden_dim=16, output_dim=1)
# 用之前的数据
Y_pred = net.forward(X)
print(f"输入形状: {X.shape}") # (1000, 5)
print(f"第一层输出形状: {net.a1.shape}") # (1000, 16)
print(f"最终输出形状: {Y_pred.shape}") # (1000, 1)
print(f"参数总量: {5*16 + 16 + 16*1 + 1} = {5*16 + 16 + 16*1 + 1}")
输出:
输入形状: (1000, 5)
第一层输出形状: (1000, 16)
最终输出形状: (1000, 1)
参数总量: 5*16 + 16 + 16*1 + 1 = 113
从5维输入到16维隐藏层到1维输出,113个参数,全靠矩阵乘法串起来。
6.3 尺寸追踪:一个实用技巧
调试神经网络时,最常见的错误是矩阵尺寸不匹配。这里有个技巧:沿着数据流追踪每一步的形状。
def shape_trace(X, W1, b1, W2, b2):
"""追踪每一步的张量形状"""
print("=== 形状追踪 ===")
print(f"输入 X: {X.shape}")
print(f"权重 W1: {W1.shape}")
z1 = X @ W1
print(f"X @ W1: {z1.shape} ← ({X.shape[0]}×{X.shape[1]}) @ ({W1.shape[0]}×{W1.shape[1]})")
z1 = z1 + b1
print(f"+ b1: {z1.shape} ← 广播加法")
a1 = np.maximum(0, z1)
print(f"ReLU(z1): {a1.shape} ← 逐元素操作,形状不变")
print(f"权重 W2: {W2.shape}")
z2 = a1 @ W2
print(f"a1 @ W2: {z2.shape} ← ({a1.shape[0]}×{a1.shape[1]}) @ ({W2.shape[0]}×{W2.shape[1]})")
z2 = z2 + b2
print(f"+ b2: {z2.shape} ← 最终输出")
shape_trace(X, net.W1, net.b1, net.W2, net.b2)
输出:
=== 形状追踪 ===
输入 X: (1000, 5)
权重 W1: (5, 16)
X @ W1: (1000, 16) ← (1000×5) @ (5×16)
+ b1: (1000, 16) ← 广播加法
ReLU(z1): (1000, 16) ← 逐元素操作,形状不变
权重 W2: (16, 1)
a1 @ W2: (1000, 1) ← (1000×16) @ (16×1)
+ b2: (1000, 1) ← 最终输出
记住这个技巧。后面学Transformer的时候,形状追踪能帮你理清很多混乱。
七、广播:numpy的"隐形规则"
7.1 什么是广播?
上面代码里有一行:z1 = X @ W1 + b1
X @ W_1 的结果是 (1000, 16),而 b_1 只是一个 (16,) 的向量。形状不一样,怎么加?
numpy的**广播(Broadcasting)**机制会自动把 b_1 扩展成 (1000, 16)——把同一个偏置复制1000份,加到每一行上。
X @ W1 的结果: b1: 相加结果:
┌─────────────┐ ┌──────┐ ┌─────────────┐
│ z₁₁ z₁₂ ... │ │b₁ b₂│ │z₁₁+b₁ z₁₂+b₂│
│ z₂₁ z₂₂ ... │ + │b₁ b₂│ = │z₂₁+b₁ z₂₂+b₂│
│ ... ... ... │ │ ... │ │ ... ... │
│ zₙ₁ zₙ₂ ... │ │b₁ b₂│ │zₙ₁+b₁ zₙ₂+b₂│
└─────────────┘ └──────┘ └─────────────┘
(1000, 16) (16,) (1000, 16)
↑ 自动复制1000行
7.2 广播规则
简单记:从右往左对齐,维度相同或为1时可广播。
# 合法广播
(1000, 16) + (16,) → (1000, 16) # b1加到每一行
(1000, 16) + (1, 16) → (1000, 16) # 同上
(1000, 1) + (1, 16) → (1000, 16) # 两边都广播
# 不合法
(1000, 16) + (15,) → 报错!16 ≠ 15
在深度学习代码里,广播无处不在。理解它能帮你少踩很多坑。
八、这些概念怎么串起来?
把今天学的内容放到AI的全景图里:
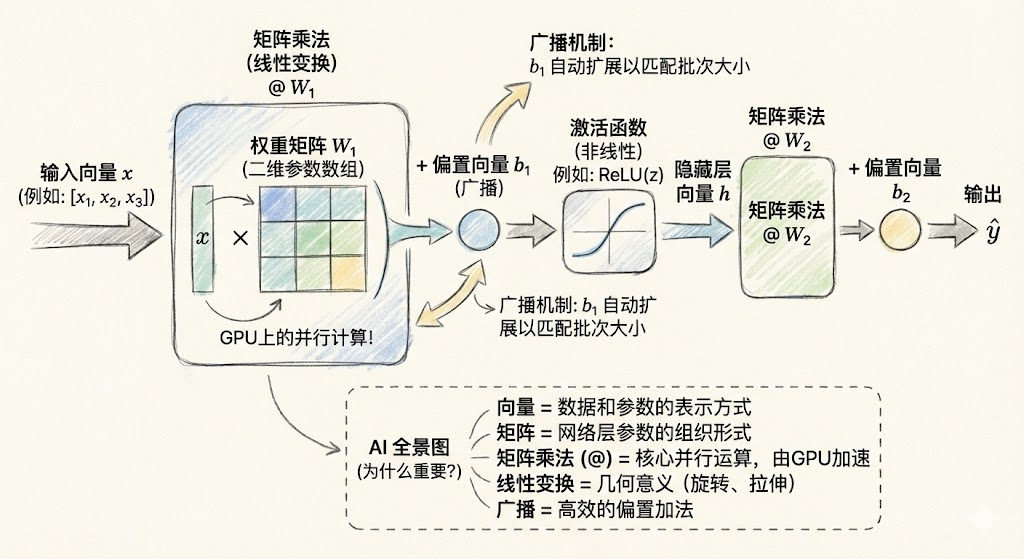
从前两篇到这一篇,我们已经掌握了AI训练的核心数学工具:
| 篇章 | 工具 | 解决的问题 |
|------|------|-----------|
| 1-1 函数与导数 | 导数、偏导数、梯度 | 知道参数往哪个方向调 |
| 1-2 梯度下降 | 梯度下降、Adam优化器 | 知道怎么一步步调参数 |
| **1-3 线性代数** | **向量、矩阵、矩阵乘法** | **知道怎么高效地算** |
---
## 九、总结
### 三个层次的理解
**第一层:直觉**
> 向量是"一组数字"。矩阵是"一堆向量"。矩阵乘法是"批量做点积"。神经网络每一层就是一次矩阵乘法。
**第二层:数学**
> 矩阵乘法实现了线性变换——对空间的旋转、拉伸、投影。加上激活函数的非线性变换,神经网络可以把数据变换到任意形状的空间。
**第三层:工程实践**
> 矩阵运算可以被GPU并行加速。把循环改成矩阵运算,速度提升几百倍。这就是为什么AI训练需要显卡。
### 关键公式卡片
向量点积: a · b = Σ(aᵢ × bᵢ)
余弦相似度: cos(θ) = (a · b) / (|a| × |b|)
矩阵乘法: (m×n) @ (n×p) = (m×p)
神经网络一层: h = ReLU(X @ W + b)
尺寸规则: 左矩阵的列数 = 右矩阵的行数
### 下期预告
下一篇:**《概率论基础:AI的"不确定性"从何而来?》**
到目前为止,我们的模型输出的是一个确定的数字(比如预测房价123万)。但AI经常需要回答的问题是:"这张图片是猫的概率是多少?"
概率论给了AI处理"不确定性"的能力。下一篇我们从高中的概率开始,讲到贝叶斯定理、概率分布,最终理解Softmax——Transformer输出层那个把"分数"变成"概率"的函数。
---
*写于2026年2月,"技术解码·数学筑基"系列第3篇。*
*从循环到矩阵,从CPU到GPU,效率提升的秘密藏在线性代数里。*
**系列导航**:
- 上篇:[[博客-技术解码-1.2-梯度下降]] 1-2 梯度下降:AI是怎么"学习"的?
- 本篇:1-3 线性代数速成:向量和矩阵为什么重要?
- 下篇:[[博客-技术解码-1.4-概率论基础]] 1-4 概率论基础:AI的"不确定性"从何而来?
评论区