


系列一 · 数学筑基 · 第1篇 | 预计阅读时间:20分钟 | 前置知识:高中数学
写在开头:从同事的一个问题说起
去年有个同事转岗做AI,兴冲冲地看了两篇论文,然后来找我:
"看不下去了,全是公式。我数学不行,是不是没戏了?"
我问他:"高中数学学过导数吗?"
"学过啊,求斜率嘛。"
"那你数学就够了。至少,够你理解AI是怎么'学习'的。"
他不信。
于是我花了一下午给他讲了一遍——从高中导数讲到梯度下降。讲完他说:"就这?我以为要学多高深的数学。"
今天这篇文章,就是那个下午的整理版。如果你有高中数学基础,读完这篇,你会明白一件事:AI的"学习",本质上就是一个不断求导、不断调整的过程。
这是"技术解码·数学筑基"系列的第一篇。我们从最简单的东西开始。
一、函数:万物皆可映射
1.1 高中就学过的东西
函数是什么?高中课本上的定义:给定一个输入 x,得到一个输出 y。
比如:
- y = 2x + 1(线性函数)
- y = x^2(二次函数)
- y = \sin(x)(三角函数)
核心思想:函数描述的是一种"映射关系"——输入变了,输出也跟着变。
这听起来太简单了,但别急,AI里的很多东西本质上就是函数。
1.2 AI里的函数长什么样?
一个最简单的AI模型——线性回归,长这样:
- x:输入(比如房子的面积)
- \hat{y}:预测值(比如预测的房价)
- w:权重(weight,斜率)
- b:偏置(bias,截距)
你看,这不就是高中学的一次函数 y = kx + b 吗?
💡 吴恩达在《Machine Learning》课程中说:线性回归是监督学习的入门,但它包含了所有机器学习的核心要素——模型、损失函数、优化算法 1。
区别在哪?
高中的时候,k 和 b 是题目给好的,你直接算 y。
但在AI里,w 和 b 是未知的——你有一堆数据(很多组 x 和 y),需要让机器自己"学"出最合适的 w 和 b。
这就是"学习"的本质:自动找到最好的参数。
| 领域 | 区别 |
|---|---|
| 高中数学 | y = kx + b(k、b 已知,求 y) |
| AI中的函数 | ŷ = wx + b(w、b 未知,从数据学习) |
1.3 从一维到多维
现实世界的问题不可能只有一个输入。预测房价,你至少要考虑面积、楼层、地段、年限......
这时候函数变成:
写成向量形式:
其中 \mathbf{w} = [w_1, w_2, ..., w_n],\mathbf{x} = [x_1, x_2, ..., x_n]。
看起来复杂了?其实没有——本质还是高中的一次函数,只不过从一条直线变成了高维空间里的一个超平面。
后面我们会看到,神经网络就是把这种函数一层层堆叠起来,中间插入一些"弯曲"操作(激活函数),让它能拟合任意复杂的关系。
但这些都是后话。现在我们回到最核心的问题:怎么找到最好的 w 和 b?
答案藏在导数里。
二、导数:变化的速度
2.1 导数的直觉
高中课本上,导数是"函数在某一点的变化率"。
翻译成人话:导数就是"此刻,x 变一点点,y 会变多少"。
💡 3Blue1Brown 在《微积分的本质》中说:导数是对"变化率"的精确度量,它告诉我们函数在每一点的敏感程度 5。
举个生活例子:
你开车,速度表显示80km/h。这个"80"就是位移函数对时间的导数——此刻,时间过一小时,你会走80公里。
对AI来说,导数回答的问题是:如果我把参数 w 调大一点点,预测结果会变好还是变差?变多少?
2.2 几个常用导数
以下是高中就学过的导数公式,在AI里会反复用到:
| 函数 f(x) | 导数 f'(x) | AI中的应用 |
|---|---|---|
| x^n | nx^{n-1} | 多项式模型 |
| e^x | e^x | Softmax、概率计算 |
| \ln(x) | \frac{1}{x} | 交叉熵损失函数 |
| \frac{1}{1+e^{-x}} | \sigma(x)(1-\sigma(x)) | Sigmoid激活函数 |
💡 斯坦福 CS231n 课程强调:掌握这些基本函数的导数是理解反向传播的基础,因为神经网络的前向传播本质上就是这些基本函数的复合 4。
最后一个 \frac{1}{1+e^{-x}} 叫 Sigmoid函数,它是神经网络里最经典的激活函数之一。你看它的导数形式非常漂亮——\sigma(x)(1-\sigma(x)),自己乘以自己的补数。后面讲反向传播的时候会用到。
2.3 导数的几何意义
导数就是函数曲线在某一点的切线斜率。
y
↑ . .
| . .
| . .
| . ← 斜率 = 导数值 .
| . .
| .
└──────────────────────────────→ x
- 导数 > 0:函数在上升(x 增大,y 也增大)
- 导数 < 0:函数在下降(x 增大,y 反而减小)
- 导数 = 0:函数到了极值点(山顶或山谷)
这个性质太重要了。因为AI的"学习"就是在找"山谷"——损失最小的地方。导数告诉我们:往哪个方向走,能下山。
三、偏导数:多个变量怎么办?
3.1 从导数到偏导数
高中的导数处理的是一个变量的函数:y = f(x)。
但AI模型有成千上万个参数(w_1, w_2, ..., w_n),怎么办?
答案很简单:一次只看一个变量,其他的当常数。
这就是偏导数:
读作"f对w1的偏导数",意思是:固定其他所有变量不变,只动 w_1,f 会怎么变。
3.2 举个例子
假设有个函数:
对 w_1 求偏导(把 w_2 当常数):
对 w_2 求偏导(把 w_1 当常数):
就这么简单:求偏导 = 普通求导 + 把其他变量当常数。
如果你会高中的导数,你就会偏导数。没有新知识,只是换了个角度。
3.3 类比理解
想象你站在一座山上,脚下是二维地形。
- 对 x 方向求偏导:你面朝东方,脚下的坡度有多陡?
- 对 y 方向求偏导:你面朝北方,脚下的坡度有多陡?
偏导数告诉你每个方向的坡度。
那么问题来了:哪个方向下坡最快?
四、梯度:最陡的下坡方向
4.1 梯度的定义
把所有偏导数放在一起,组成一个向量,就是梯度:
还是刚才那个例子:
梯度:
梯度是一个向量,它有方向,有大小。
💡 《Deep Learning》教材(Goodfellow et al.)指出:梯度是优化理论的核心概念,它指向函数值增长最快的方向,这一性质是所有梯度下降算法的基础 3。
4.2 梯度的几何意义
梯度指向函数值增长最快的方向。
反过来说:负梯度方向,就是函数值下降最快的方向。
回到山的类比:
- 梯度 = 最陡的上坡方向
- 负梯度 = 最陡的下坡方向
如果你想找到山谷(损失最小的地方),只需要每一步都沿着负梯度方向走。
这就是梯度下降的核心思想。我们下一篇会详细展开。
4.3 梯度的大小
梯度向量的长度(模)表示"坡度有多陡":
- 梯度大 → 坡很陡 → 离山谷还远
- 梯度小 → 坡很平 → 快到山谷了(或者到了一个平原)
- 梯度为零 → 到了极值点(山顶、山谷或鞍点)
五、代码验证:让数学"跑"起来
光说不练假把式。咱们用Python验证上面的每一个概念。
5.1 导数的数值验证
import numpy as np
# 函数:f(x) = x^2
def f(x):
return x ** 2
# 解析导数:f'(x) = 2x
def f_derivative(x):
return 2 * x
# 数值导数:用极限定义近似
def numerical_derivative(f, x, delta=1e-7):
return (f(x + delta) - f(x)) / delta
# 验证:在 x=3 处
x = 3.0
print(f"解析导数: f'(3) = {f_derivative(x)}")
print(f"数值导数: f'(3) ≈ {numerical_derivative(f, x):.6f}")
print(f"误差: {abs(f_derivative(x) - numerical_derivative(f, x)):.2e}")
输出:
解析导数: f'(3) = 6.0
数值导数: f'(3) ≈ 6.000000
误差: 4.99e-08
解读:数值导数和解析导数几乎完全一致,误差在 10^{-8} 量级。这意味着导数的极限定义确实是对的——\Delta x 取得足够小,\frac{\Delta y}{\Delta x} 就趋近于导数。
5.2 偏导数的数值验证
# 函数:f(w1, w2) = w1^2 + 3*w1*w2 + w2^2
def f_multi(w1, w2):
return w1**2 + 3*w1*w2 + w2**2
# 解析偏导
def df_dw1(w1, w2):
return 2*w1 + 3*w2
def df_dw2(w1, w2):
return 3*w1 + 2*w2
# 数值偏导
def numerical_partial(f, w1, w2, var='w1', delta=1e-7):
if var == 'w1':
return (f(w1 + delta, w2) - f(w1, w2)) / delta
else:
return (f(w1, w2 + delta) - f(w1, w2)) / delta
# 验证:在 (w1=2, w2=1) 处
w1, w2 = 2.0, 1.0
print("=== 偏导数验证 ===")
print(f"∂f/∂w1 解析值: {df_dw1(w1, w2)}")
print(f"∂f/∂w1 数值值: {numerical_partial(f_multi, w1, w2, 'w1'):.6f}")
print(f"∂f/∂w2 解析值: {df_dw2(w1, w2)}")
print(f"∂f/∂w2 数值值: {numerical_partial(f_multi, w1, w2, 'w2'):.6f}")
输出:
=== 偏导数验证 ===
∂f/∂w1 解析值: 7.0
∂f/∂w1 数值值: 7.000001
∂f/∂w2 解析值: 8.0
∂f/∂w2 数值值: 8.000001
解读:偏导数确实就是"固定其他变量,对一个变量求导"。数值验证完美吻合。
5.3 梯度的可视化
import numpy as np
import matplotlib.pyplot as plt
# 函数:f(x, y) = x^2 + y^2(最简单的碗形函数)
def f_bowl(x, y):
return x**2 + y**2
# 梯度:∇f = [2x, 2y]
def gradient_bowl(x, y):
return np.array([2*x, 2*y])
# 创建网格
x = np.linspace(-3, 3, 20)
y = np.linspace(-3, 3, 20)
X, Y = np.meshgrid(x, y)
Z = f_bowl(X, Y)
# 计算梯度场
U = 2 * X # ∂f/∂x
V = 2 * Y # ∂f/∂y
# 画图
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 左图:等高线
ax1 = axes[0]
contour = ax1.contour(X, Y, Z, levels=15, cmap='viridis')
ax1.clabel(contour, inline=True, fontsize=8)
ax1.set_title('f(x, y) = x² + y² (contour)')
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax1.set_aspect('equal')
ax1.plot(0, 0, 'r*', markersize=15, label='minimum')
ax1.legend()
# 右图:梯度场(箭头指向上坡方向)
ax2 = axes[1]
ax2.contour(X, Y, Z, levels=15, cmap='viridis', alpha=0.3)
ax2.quiver(X, Y, -U, -V, color='red', alpha=0.6, scale=50)
ax2.set_title('negative gradient field (downhill)')
ax2.set_xlabel('x')
ax2.set_ylabel('y')
ax2.set_aspect('equal')
ax2.plot(0, 0, 'r*', markersize=15, label='minimum')
ax2.legend()
plt.tight_layout()
plt.savefig('gradient_visualization.png', dpi=150, bbox_inches='tight')
plt.show()
print("图已保存")
这张图说了什么?
- 左图:等高线,越靠近中心函数值越小(碗底)
- 右图:红色箭头是负梯度方向,所有箭头都指向碗底
这就是梯度的几何意义:负梯度方向 = 最快到达最低点的方向。
5.4 梯度下降的预告:一步一步走下山
# 一个最简单的梯度下降演示
def gradient_descent_demo(start_x, start_y, learning_rate=0.1, steps=20):
"""从起点出发,沿负梯度方向走,看能不能走到碗底"""
x, y = start_x, start_y
path = [(x, y, f_bowl(x, y))]
for i in range(steps):
# 计算梯度
grad = gradient_bowl(x, y)
# 沿负梯度方向走一步
x = x - learning_rate * grad[0]
y = y - learning_rate * grad[1]
path.append((x, y, f_bowl(x, y)))
return path
# 从 (2.5, 2.5) 出发
path = gradient_descent_demo(2.5, 2.5, learning_rate=0.1, steps=20)
print("=== 梯度下降过程 ===")
print(f"{'步数':>4} | {'x':>8} | {'y':>8} | {'f(x,y)':>10}")
print("-" * 40)
for i, (x, y, fval) in enumerate(path):
if i <= 5 or i >= 18: # 只打印前几步和最后几步
print(f"{i:4d} | {x:8.4f} | {y:8.4f} | {fval:10.6f}")
elif i == 6:
print(f"{'...':>4} | {'...':>8} | {'...':>8} | {'...':>10}")
print(f"\n起点: f(2.5, 2.5) = {f_bowl(2.5, 2.5)}")
print(f"终点: f({path[-1][0]:.6f}, {path[-1][1]:.6f}) = {path[-1][2]:.10f}")
print(f"真实最小值: f(0, 0) = 0")
输出:
=== 梯度下降过程 ===
步数 | x | y | f(x,y)
----------------------------------------
0 | 2.5000 | 2.5000 | 12.500000
1 | 2.0000 | 2.0000 | 8.000000
2 | 1.6000 | 1.6000 | 5.120000
3 | 1.2800 | 1.2800 | 3.276800
4 | 1.0240 | 1.0240 | 2.097152
5 | 0.8192 | 0.8192 | 1.342177
... | ... | ... | ...
18 | 0.0337 | 0.0337 | 0.002271
19 | 0.0270 | 0.0270 | 0.001453
20 | 0.0216 | 0.0216 | 0.000930
起点: f(2.5, 2.5) = 12.5
终点: f(0.021600, 0.021600) = 0.0009338880
真实最小值: f(0, 0) = 0
看到了吗?
从 (2.5, 2.5) 出发,每一步都沿着负梯度方向走,函数值从 12.5 一路下降到接近 0。
20步之后,已经非常接近最小值点 (0, 0) 了。
这就是AI"学习"的本质——不断计算梯度,不断调整参数,让损失越来越小。
下一篇我们会详细展开梯度下降的各种细节:学习率怎么选?走太快会怎样?走太慢又会怎样?局部最优怎么办?
五、概念全景图:从函数到梯度的思维导图
在深入AI应用之前,让我们用一张图串联今天学到的所有概念:
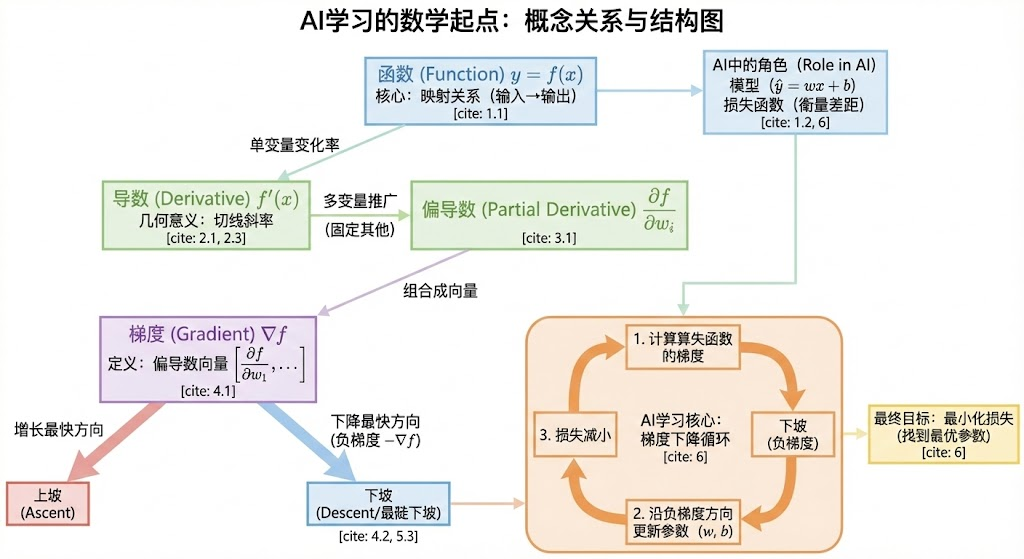
这张思维导图展示了AI数学基础的四个核心概念及其关联:
- 函数:一切的基础,描述"输入→输出"的映射关系
- 导数:衡量变化的速度,告诉我们"往哪个方向调整"
- 偏导数:多变量世界的导数,每个方向单独看坡度
- 梯度:所有偏导数的组合,指向"最陡的下坡方向"
四个概念环环相扣:函数 → 导数 → 偏导数 → 梯度,每一步都是自然的延伸,没有跳跃。
这就是为什么我说"高中数学就够了"——思维导图的根基,就是你高中学过的函数和导数。
六、这些数学在AI里到底怎么用?
来做一个全景串联,把今天学的东西和AI的"学习"过程对应起来:
AI的学习过程:
1. 定义模型 ──→ 选一个函数形式(比如 ŷ = wx + b)
↑ 就是"函数"
2. 定义损失 ──→ 衡量预测和真实值的差距
↑ 也是一个"函数"(损失函数)
3. 计算梯度 ──→ 损失函数对每个参数的偏导数
↑ 就是"偏导数"和"梯度"
4. 更新参数 ──→ 沿负梯度方向调整参数
↑ 就是"梯度下降"
5. 重复3-4 ──→ 直到损失足够小
对应关系:
| 高中/大学数学 | AI中的角色 |
|---|---|
| 函数 f(x) | 模型本身,也是损失函数 |
| 导数 f'(x) | 参数的调整方向和幅度 |
| 偏导数 \frac{\partial f}{\partial w_i} | 某个参数对损失的影响 |
| 梯度 \nabla f | 所有参数的最优调整方向 |
| 极值点 | 损失最小的参数组合(训练目标) |
一句话总结:AI的"学习" = 定义一个损失函数 + 用梯度找到它的最小值。
就这么简单。
九、为什么从这些开始?
你可能会问:就这几个概念,值得写一整篇文章吗?
值得。因为在后面的系列中,你会发现它们无处不在:
- 系列一第2篇·梯度下降:今天的梯度预告会展开成完整的优化算法
- 系列一第6篇·反向传播:整个神经网络的训练核心就是链式法则求梯度
- 系列二·神经网络:每一层都是一个函数,层层嵌套
- 系列三·Transformer:Attention的计算离不开矩阵运算和Softmax(e^x 的导数)
- 系列五·训练大模型:几十亿参数的梯度更新,用的还是今天这套逻辑
万丈高楼平地起。今天打下的地基,后面每一层都用得到。
七、思考与练习
理解最好的方式是动手。这里有几个问题,帮你检验自己的掌握程度:
7.1 基础题
-
Sigmoid导数推导:为什么 \sigma(x) = \frac{1}{1+e^{-x}} 的导数可以表示为 \sigma(x)(1-\sigma(x))?
- 提示:用商的导数法则,或者写成 (1+e^{-x})^{-1} 用链式法则
-
梯度的方向:如果一个函数在某点的梯度为零向量,它一定是最小值点吗?
- 提示:想想山顶(最大值)和鞍点(一个方向上升,另一个方向下降)
-
学习率实验:对于 f(x,y)=x^2+y^2,从 (-2, -2) 出发:
- 学习率设为 0.1,会发生什么?
- 学习率设为 0.5,会发生什么?
- 学习率设为 1.1,会发生什么?
7.2 进阶题
-
链式法则预演:如果有 h(x) = f(g(x)),那么 h'(x) 等于什么?
- 这是我们下一篇要讲的链式法则,可以先猜一猜
-
多维直觉:想象一个三维函数 f(x,y) 的图像像个碗:
- 在碗的最低点,梯度是什么?
- 在碗的边缘,梯度指向哪里?
- 如果你在碗内任意位置,怎么走到碗底?
7.3 代码实践
运行文中的梯度下降代码,尝试修改以下参数,观察结果:
# 实验1:不同起点
path1 = gradient_descent_demo(2.5, 2.5, learning_rate=0.1, steps=20)
path2 = gradient_descent_demo(-2, -2, learning_rate=0.1, steps=20)
path3 = gradient_descent_demo(0.1, 3, learning_rate=0.1, steps=20)
# 实验2:不同学习率
path_fast = gradient_descent_demo(2.5, 2.5, learning_rate=0.5, steps=20)
path_slow = gradient_descent_demo(2.5, 2.5, learning_rate=0.01, steps=20)
💡 预期现象:学习率太大可能"震荡"(来回跳跃),学习率太小收敛很慢。下一篇我们会详细讨论这个问题。
八、总结
三个层次的理解
第一层:直觉
函数描述"输入→输出"的关系。导数衡量"变化的速度"。梯度指出"最快的方向"。
第二层:数学
偏导数是多变量函数对单个变量的导数。梯度是所有偏导数组成的向量,指向函数值增长最快的方向。
第三层:AI应用
AI的学习 = 定义损失函数 + 沿负梯度方向迭代更新参数 + 直到损失最小。
关键公式卡片
导数定义: f'(x) = lim[Δx→0] (f(x+Δx) - f(x)) / Δx
偏导数: ∂f/∂wᵢ = 固定其他变量,对wᵢ求导
梯度: ∇f = [∂f/∂w₁, ∂f/∂w₂, ..., ∂f/∂wₙ]
梯度方向: ∇f 指向函数值增长最快的方向
-∇f 指向函数值下降最快的方向
下期预告
下一篇:《梯度下降:AI是怎么"学习"的?》
我们会详细展开梯度下降算法——学习率怎么选、走太快会"震荡"、走太慢会"龟速"、遇到鞍点怎么办。还会手写一个完整的线性回归训练过程。
从此以后,每次你听到"模型在训练",你就知道它在干什么了。
写于2026年2月,"技术解码·数学筑基"系列第1篇。
从高中导数出发,到AI的数学起点。大道至简,不过如此。
系列导航:
- 本篇:1-1 函数、导数与梯度
- 下篇:[[博客-技术解码-1.2-梯度下降]] 1-2 梯度下降:AI是怎么"学习"的?
- 系列总纲:[[0-技术解码-系列总纲]]
📚 参考文献
推荐延伸阅读
- 直观理解微积分:3Blue1Brown - 微积分的本质(B站搬运)
- 梯度下降可视化:_gradient descent visualization - 交互式演示
- 数学符号速查:Mathematics for ML - 《机器学习的数学》免费电子书
Andrew Ng. Machine Learning (Coursera). Week 1: Linear Algebra Review; Week 2: Gradient Descent. https://www.coursera.org/learn/machine-learning ↩
Stanford CS229: Machine Learning. Lecture Notes 1: Linear Regression; Lecture Notes 2: Gradient Descent. http://cs229.stanford.edu/
Ian Goodfellow, Yoshua Bengio, Aaron Courville. Deep Learning. MIT Press, 2016. Chapter 4: Numerical Computation; Chapter 6: Deep Feedforward Networks. https://www.deeplearningbook.org/ ↩
Stanford CS231n: Convolutional Neural Networks for Visual Recognition. Lecture 3: Loss Functions and Optimization. http://cs231n.stanford.edu/ ↩
Grant Sanderson (3Blue1Brown). Essence of Calculus. Series on derivatives, limits, and the intuition of calculus. https://www.3blue1brown.com/topics/calculus ↩
斯坦福深度学习官网. CS231n 网络资源. http://cs231n.github.io/optimization-1/
评论区